Scraper is a pretty good Chrome extension I use on a regular basis to quickly extract links from a page. Unfortunately, there can be rare instances where it actually takes more effort to use.
For example, if I wanted to retrieve all links from Hewlett-Packard’s HTML sitemap, I would need to create multiple Google spreadsheets to capture that data because of the way the page is structured. In this particular case, I’d have to scrape the page a total of 14 times to account for the different sections.
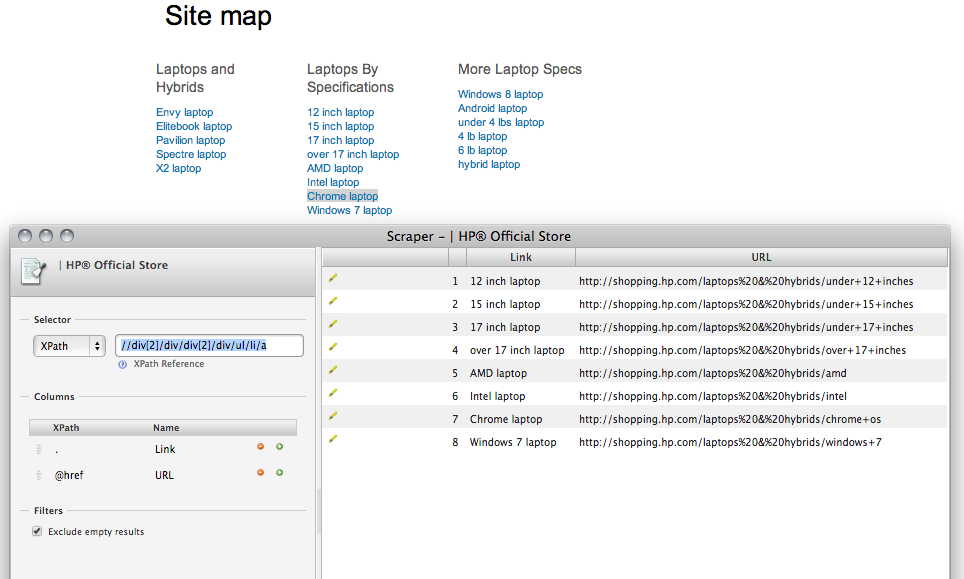
scraper_example
With Ruby and Nokogiri though (an amazing web parsing Ruby gem that I could never do without), I can effortlessly extract all links from any given page with just a few lines of code. With that in mind, the code block below is what I used to accomplish this task.
require 'nokogiri'
require 'open-uri'
url = "http://shopping.hp.com/en_US/home-office/-/static/page-sitemap"
page = Nokogiri::HTML(open(url))
links = page.css('div.gd-grid-4 a').map { |link| link['href']}
puts linksA couple things to note if you decide to use this: the first is you obviously want to change the “url” variable (line 5) to your target web page. The second is revising the “div.gd-grid-4” part (line 9) - this is dependent on how the target page was developed so you’ll need some developer tools to get your own answer here.
Let me know what you think or if you have any questions. Enjoy!