Remember the telephone game? One person whispers a message, it passes through a chain of people, and by the end “ogether we will make a world of difference” becomes simply “haaaaa.”
We’re playing the same game with artificial intelligence now — except the output sounds polished at every step.
That’s what makes it dangerous.
Anecdotal evidence
On a recent project, someone used an LLM to draft a strategy document. A second person took that output and fed it back into an LLM to build on it. A third person layered their own AI-assisted revisions on top. A fourth reviewed the latest version…also with AI. Then the original author looped that version back into the LLM to come up with the “final” version.
By the end of this cycle we had a document that read beautifully, flowed logically, but was built on a foundational assumption that nobody verified anything. At no point in this chain did someone stop and ask: is this thing we’re writing actually true?
The initial draft assumed a critical workflow operated a certain way. It sounded “right” because LLMs are exceptionally good at generating plausible-sounding reasoning. Each subsequent iteration within ChatGPT and Claude reinforced those assumptions, adding layers of increasingly sophisticated analysis on top of a broken foundation.
The entire document was scrapped and rebuilt from scratch. Not because AI is bad at developing strategy but because the team outsourced the one thing AI can’t do: validate assumptions against reality.
This was the agentic telephone game playing out in slow motion, with humans manually doing what automated agentic chains will soon do at scale.
Compounding drift
Compounding errors in LLMs are well-documented at the technical level where small inaccuracies in token prediction cascade through subsequent outputs. But the same dynamic plays out at the individual workflow level when teams layer AI output on AI output without human-in-the-loop checkpoints.
I think of this as compounding drift: each pass introduces small gaps in accuracy or context. The LLM models fill those gaps with confident, articulate reasoning that sounds “about” right. And because the output reads so well, nobody questions its entirety.
Assuming each interaction preserves approximately 92% of the accuracy of the input, we don’t stay at 92%. This is compounded…but in the opposite direction.
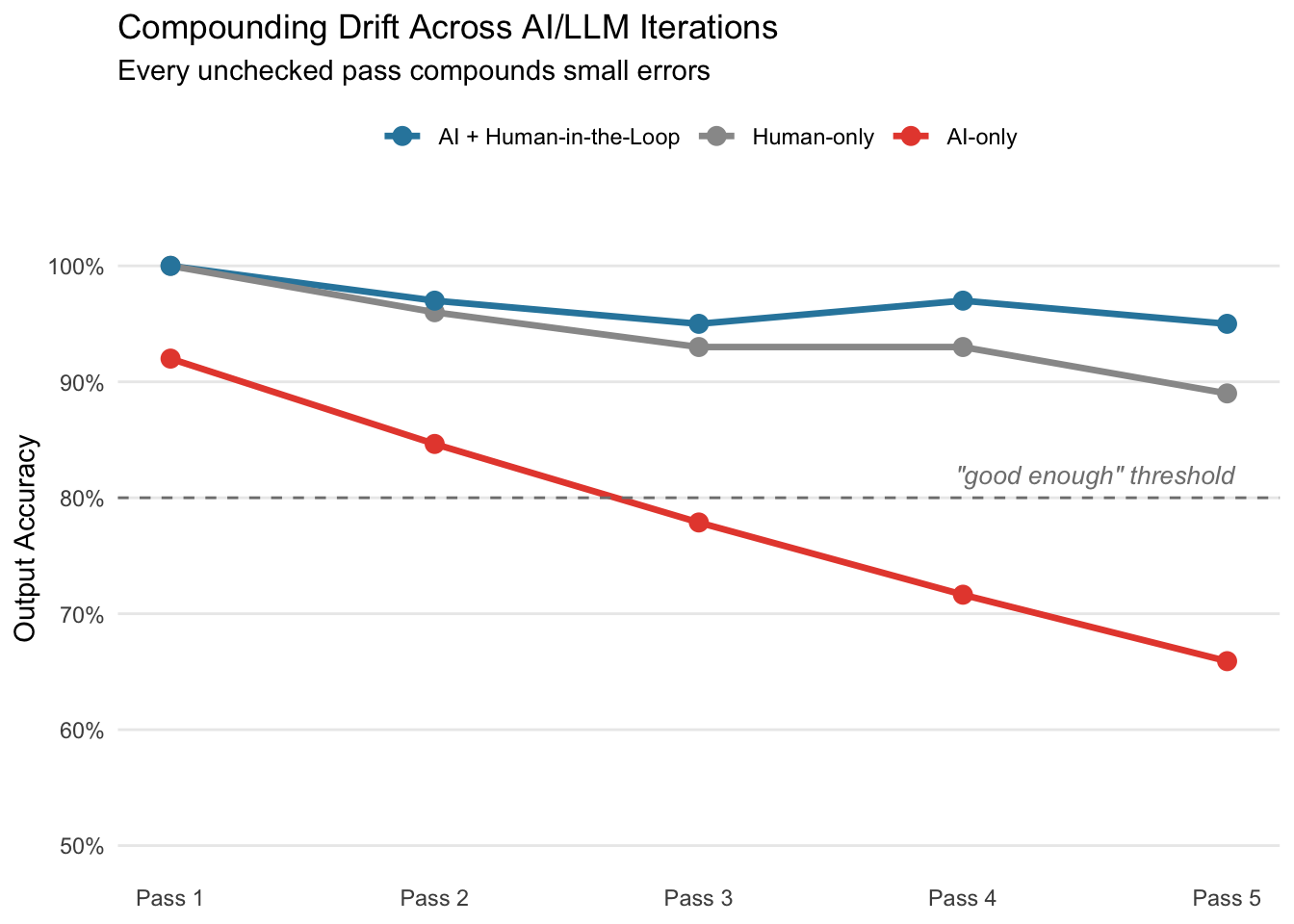
A few highlights on the above:
- Red: four rounds of AI-on-AI and we’re at ~72% accuracy even if the output LOOKS like it’s at 100%.
- Gray: humans drift too but slower since we can self-correct. If something feels off on Pass 3 we go back and check.
- Blue: best of both worlds where we let AI handle the production work but keep humans verifying the assumptions everything depends on. This ensures the decay stays within a recoverable range because someone is resetting the foundation at each checkpoint.
The future of work (?)
What I described above was humans manually passing AI output between themselves. It was slow enough that someone could have, should have, and would have caught the problem…but they didn’t.
Fully agentic workflows remove even that possibility.
When we chain agents together - one drafting, another analyzing, a third summarizing, a fourth making recommendations - we get the same compounding drift but faster and with no natural friction point. No one gets to raise a flag about their gut feeling that something’s off on pass 3. No one paused to ask whether the methodology is sound. The entire chain just runs.
The human telephone game I witnessed took days to play out across multiple Slack threads. An agentic version of the same workflow runs in minutes. Same drift but with collapsed timelines and zero opportunity for organic course-correction.
Of course, this doesn’t mean agentic workflows are a bad idea. It means the human-in-the-loop verification architecture matters more than the automated systems. Where we place the human checkpoint in an agentic chain determines whether we get compounding intelligence or compounding hallucination.
Decoupling effort from quality
The deeper issue underneath all of this: AI/LLMs haven’t just reduced effort but decoupled effort from quality in a way we’re not calibrated for.
Pre-AI, there was a rough correlation between how much work we put into something and how good it was. For example, an estimated 8 hour deliverable meant research, thinking, pulling data, validating analysis, framing the narrative, and then actually writing the document. The effort was the quality mechanism.
Now we can produce a visually equivalent output in 20 minutes or less. But the thinking that used to be embedded in the effort? It is now optional and from my experience most people are opting out.
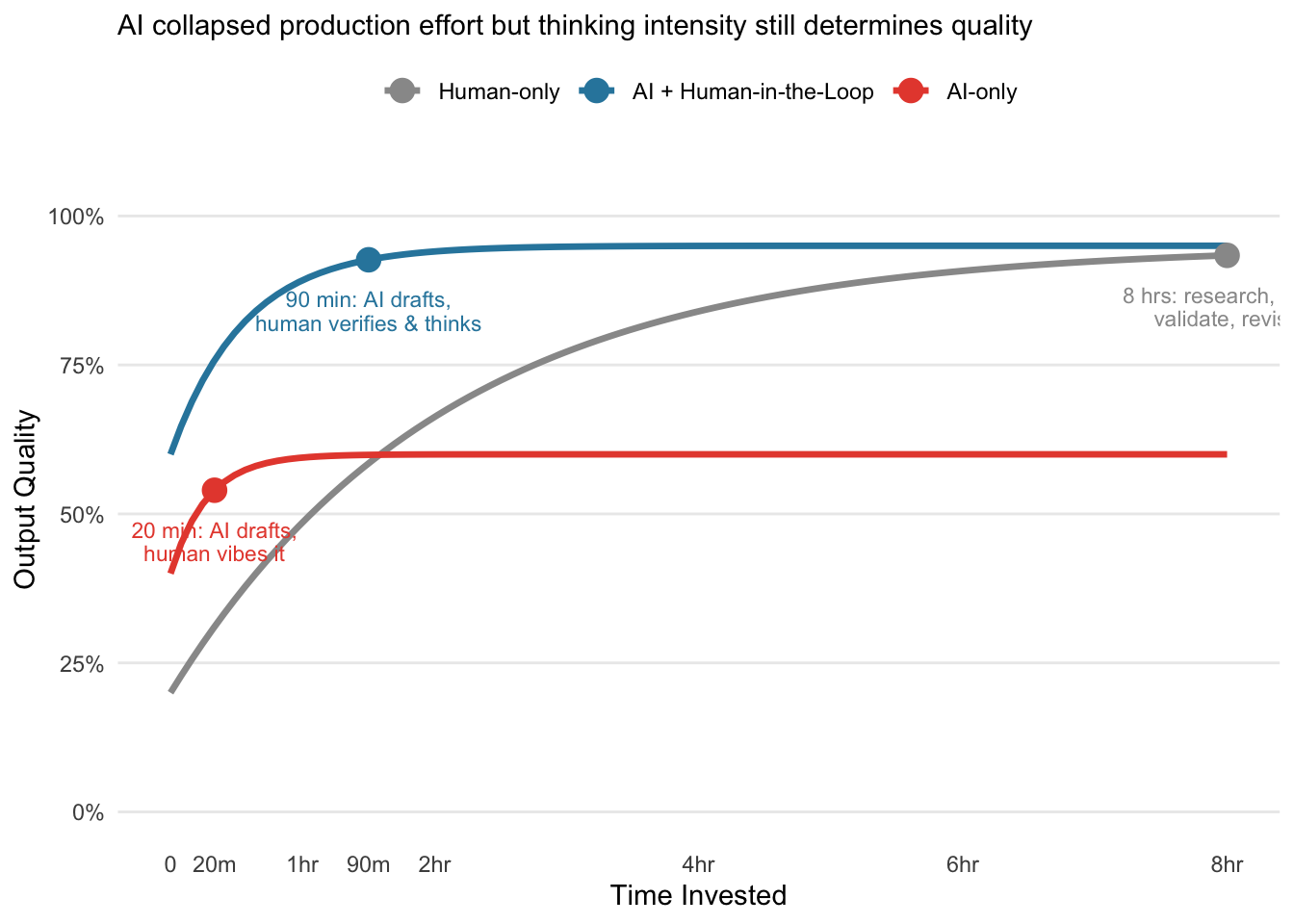
The gap between the blue and red lines is human thinking where they use the same AI application, tools, and speed. The only variable is whether someone stopped to verify the parts that matter.
In a fully agentic context and application this gap widens further. When agents handle the end-to-end production cycle, the only value humans add is the thinking portion to confirm assumptions, check alignment with reality, and make judgment calls the model can’t. If we automate away the human checkpoint then we haven’t optimized the workflow….only removed the quality mechanism entirely.
Lesson learned
I’m a fan of AI/LLM products and I personally enjoy building agentic workflows to increase my productivity. This isn’t an argument against any of that.
The telephone game didn’t break because any single person was careless. It broke because the chain had no verification step, and the same principle applies to the future of leveraging agentic workflows.
This is why I am a big fan of smaller, modular agents rather than long end-to-end chains. Smaller steps with human-in-the-loop confirmation between each subagent are easier to verify than one massive, ambiguous prompt where drift compounds invisibly.
Our end goal isn’t to “use less AI” but to never confuse production work for thinking work.